1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
| import requests
import json
from pymongo import MongoClient
import time
import csv
import pymysql
def get_json(page, condition, image_type):
page += 1
key = ''
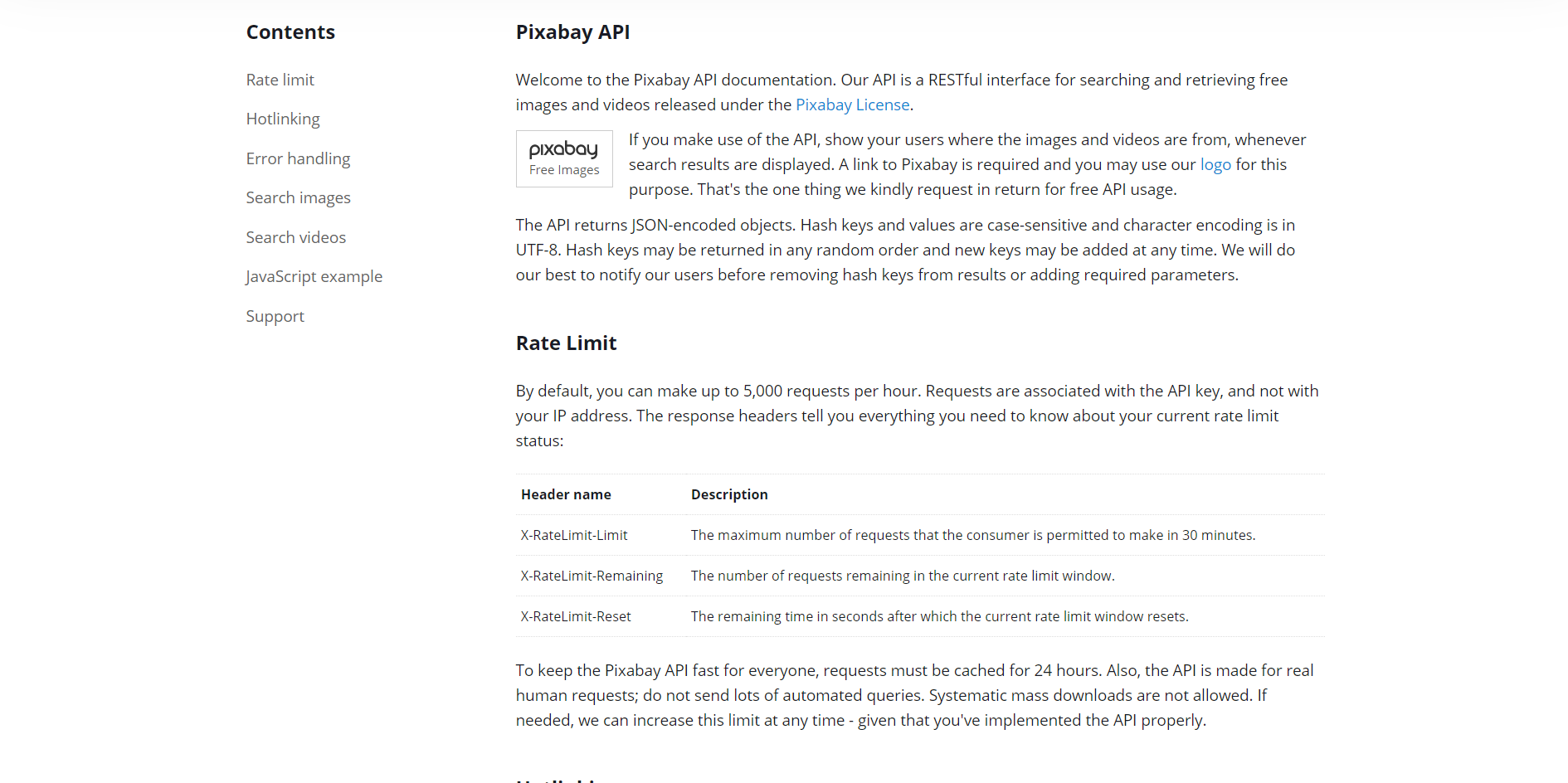
url = 'https://pixabay.com/api/'
pa = {
'key': key,
'q': condition,
'image_type': image_type,
'lang': 'zh',
'page': page,
'per_page': 200,
}
r = requests.get(url, params=pa, headers=headers)
decode_json = json.loads(r.text)
return decode_json
page = 0
id = 0
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/78.0.3904.97 Safari/537.36'}
condition = input("请输入你的搜索条件(多个条件以+连接): ")
image_type = input("请输入搜索图片类型( 'all, photo, illustration插图, vector矢量'): ")
number = input('请输入想要查询的图片页数num (num*200每页200条数据): ')
client = MongoClient('localhost', 27017)
db = client.pixabay_database
collection = db.pixabay
for _ in range(1, int(number)):
decode_json = get_json(page, condition, image_type)
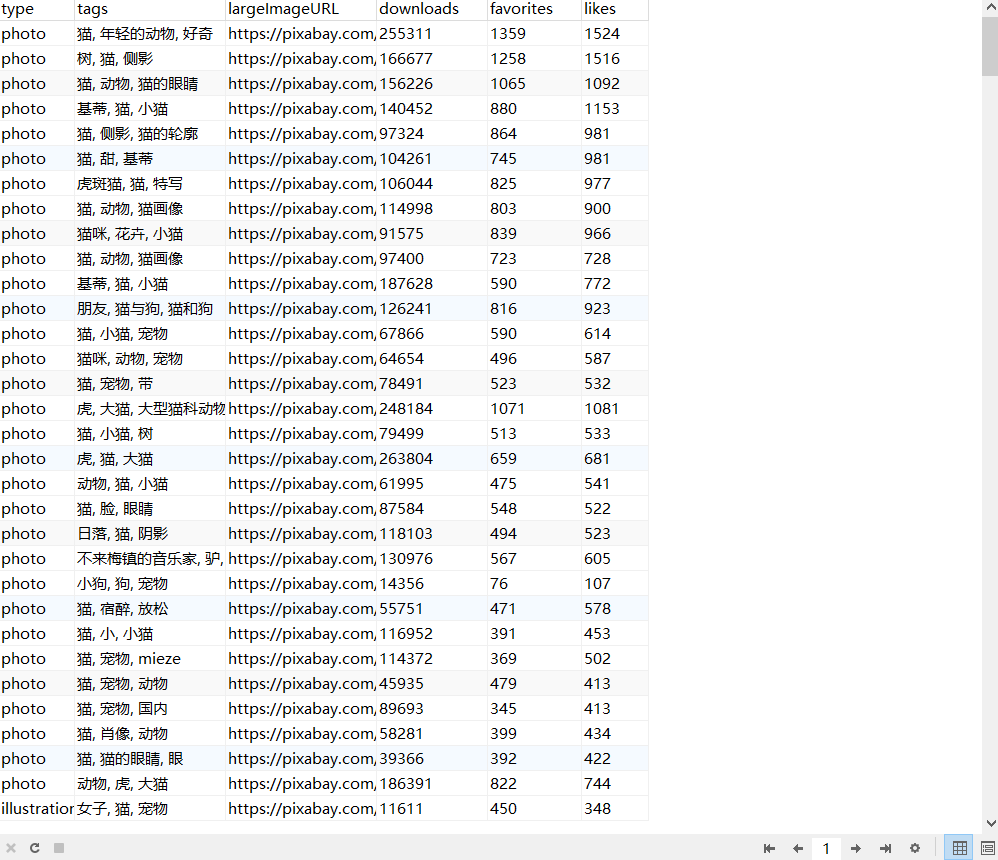
for picture in decode_json['hits']:
id += 1
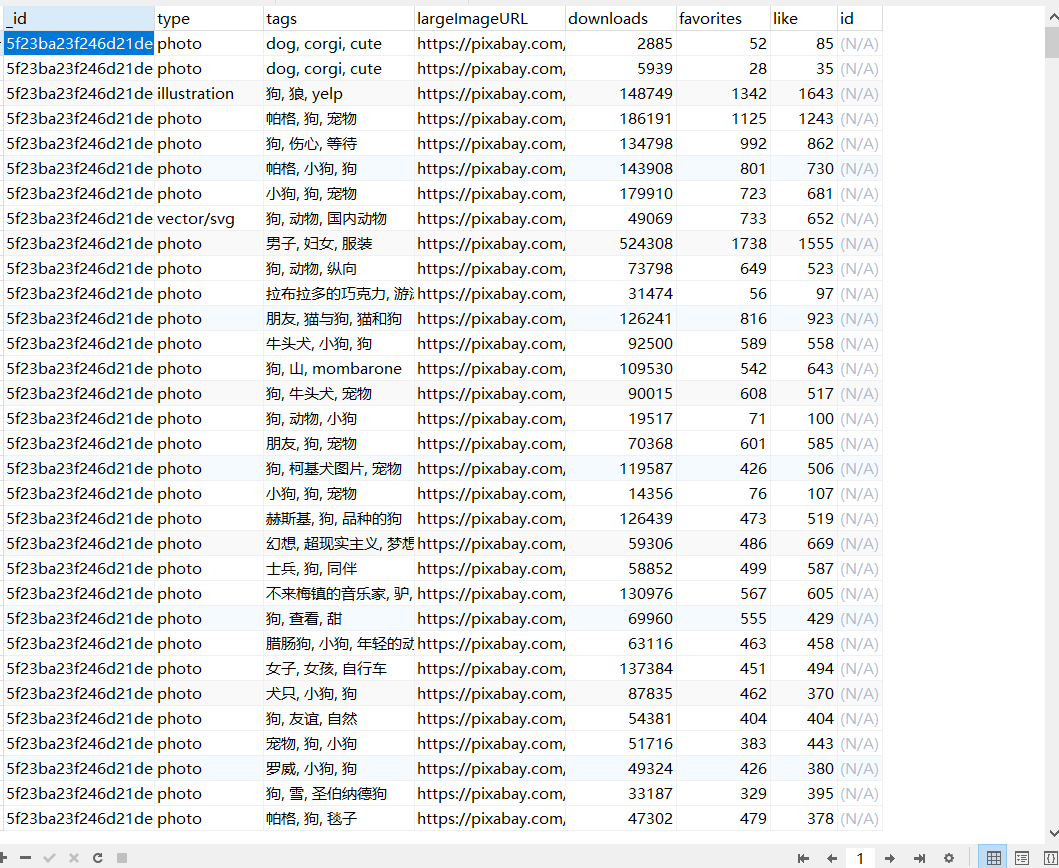
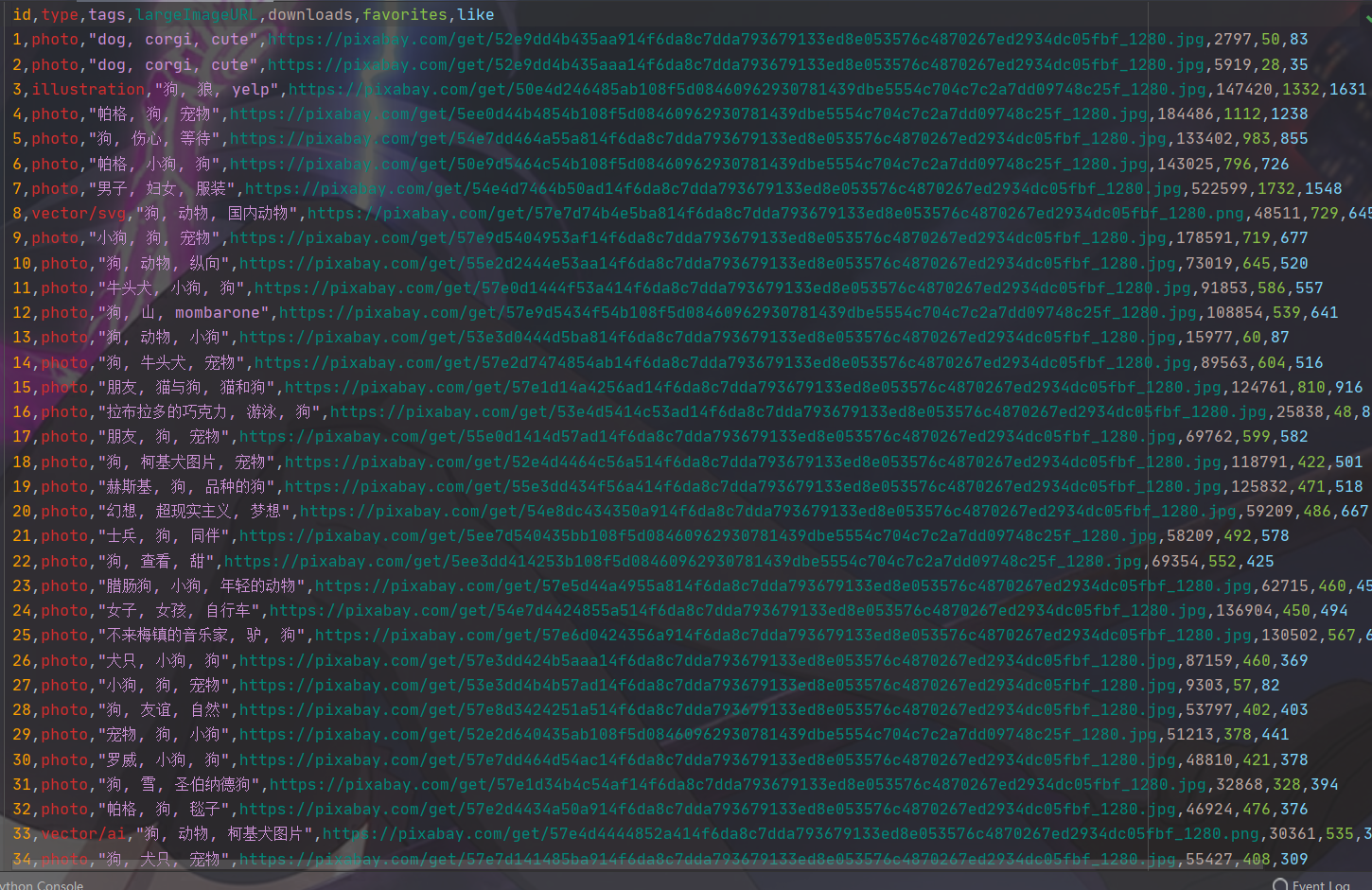
data = {'id': id,
'type': picture['type'],
'tags': picture['tags'],
'largeImageURL': picture['largeImageURL'],
'downloads': picture['downloads'],
'favorites': picture['favorites'],
'like': picture['likes'],
}
print('开始存入数据库')
collection.insert_one(data)
'''db = pymysql.connect(host='localhost',
user="root",
passwd="root",
port=3306,
db='pixabay',
charset='utf8')
cursor = db.cursor()
for _ in range(1, int(number)):
decode_json = get_json(page, condition, image_type)
for picture in decode_json['hits']:
id += 1
data = {'id': id,
'type': picture['type'],
'tags': picture['tags'],
'largeImageURL': picture['largeImageURL'],
'downloads': picture['downloads'], # 下载总数
'favorites': picture['favorites'], # 收藏夹总数
'like': picture['likes'], # 点赞总数
}
print('开始存入数据库')
sql = """INSERT INTO pixabay
(type, tags, largeImageURL, downloads, favorites, likes)
VALUES
(%s, %s, %s, %s, %s, %s)
"""
cursor.execute(sql, (
picture['type'], picture['tags'], picture['largeImageURL'], picture['downloads'], picture['favorites'],
picture['likes']))
db.commit()
# print(data)
cursor.close()
db.close()'''
'''with open('/helper_hu/analysis_pixabay/analysis_pixabay.csv', 'a+', encoding='UTF-8', newline='') as csvfile:
head = ['id', 'type', 'tags', 'largeImageURL', 'downloads', 'favorites', 'like']
writer = csv.writer(csvfile)
writer.writerow(head)
for _ in range(1, int(number)):
decode_json = get_json(page, condition, image_type)
for picture in decode_json['hits']:
id += 1
data = {'id': id,
'type': picture['type'],
'tags': picture['tags'],
'largeImageURL': picture['largeImageURL'],
'downloads': picture['downloads'], # 下载总数
'favorites': picture['favorites'], # 收藏夹总数
'like': picture['likes'], # 点赞总数
}
# head = list(data.keys())
rows = list(data.values())
writer.writerow(rows)
print('写入数据id={}'.format(id))
time.sleep(1.0)
'''
|